|
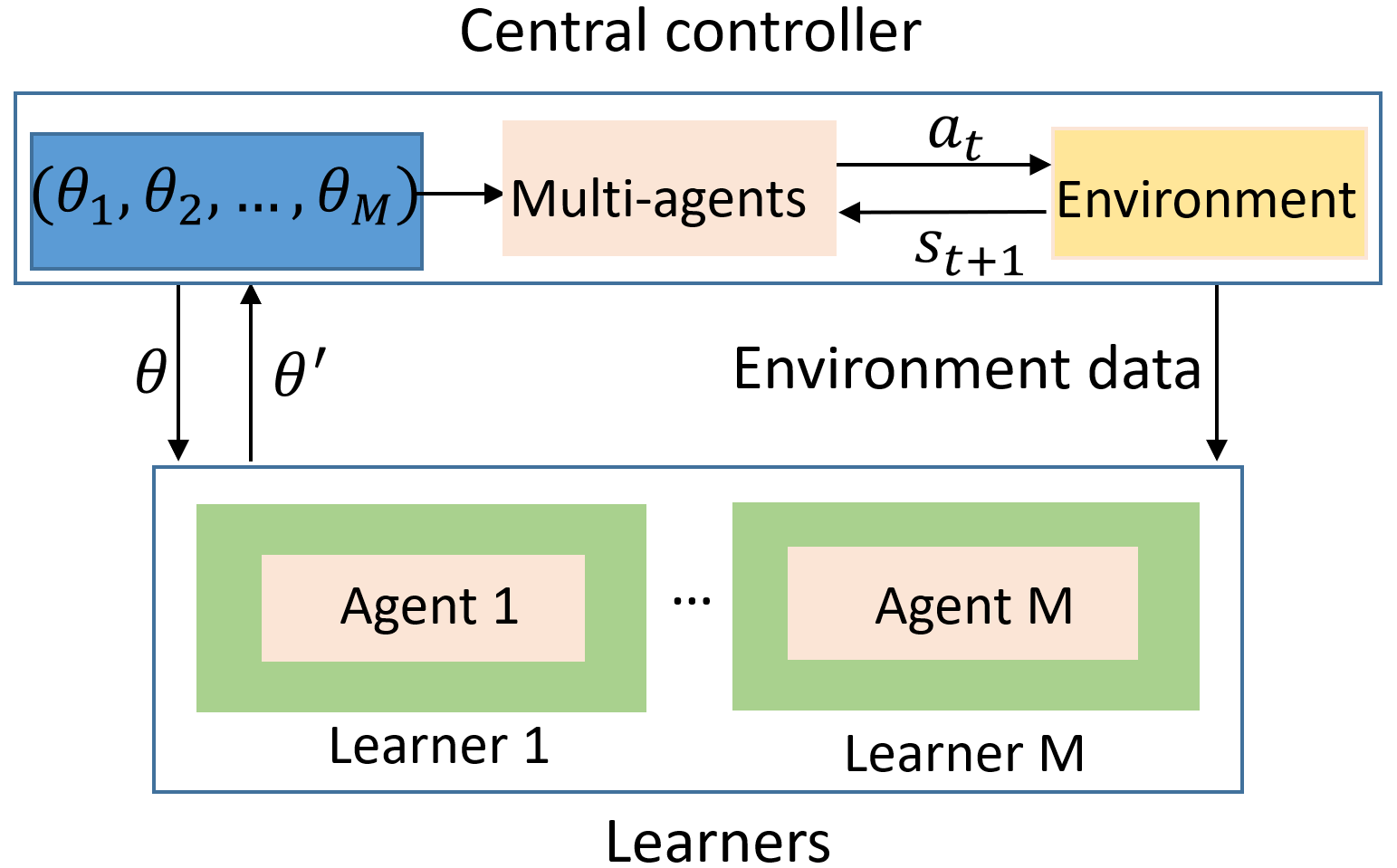
This paper aims to mitigate straggler effects in synchronous distributed learning for multi-agent reinforcement learning (MARL) problems. Stragglers arise frequently in a distributed learning system, due to the existence of various system disturbances such as slow-downs or failures of compute nodes and communication bottlenecks. To resolve this issue, we propose a coded distributed learning framework, which speeds up the training of MARL algorithms in the presence of stragglers, while maintaining the same accuracy as the centralized approach. As an illustration, a coded distributed version of the multi-agent deep deterministic policy gradient (MADDPG) algorithm is developed and evaluated. Different
coding schemes, including maximum distance separable (MDS) code, random sparse code, replication-based code, and regular low density parity check (LDPC) code are also investigated.
Simulations in several multi-robot problems demonstrate the promising performance of the proposed framework.
|